Moving left in AWS
What can go wrong does go wrong.
Our initial CI pipeline looked very much like this:

The test stage was quite comprehensive, tested on a variety of in-house systems and gave a high degree of confidence that the system would work as expected. We were happy that the result from that stage could be uploaded to EC2 and the AMI was good to go.
…you can see the problem here though…
We had tested that the product was good, but not that the product was good on EC2.
So what goes wrong?
Lots of stuff! Lots and lots of stuff…

- Startup failures due to block devices
- Startup failures due to network devices
- Weird I/O errors
- Provisioning sizing errors
- Connectivity errors
- …
The most interesting failure was one that occurred when using wimlib
(see this post). It seems
that certain files would simply not be available due to I/O errors - but the system would
boot and look, at first glance, like it was OK. Nasty.
Whilst not many of these require fixes to the initial build, some do… and then we’re in for a wait.
A better pipeline
The first thing to do was to rejig the pipeline to this:
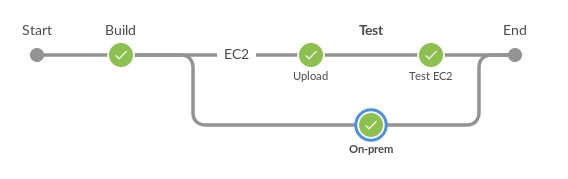
Which meant that we could catch the EC2 failures as early as possible… but that presented another problem… we couldn’t get any information about the failures.
Catching failures on EC2
The most important change was updating our Upload step to perform some very simple sanity checks:
- Can I ping the service on the required port?
- Can I send a REST call to the service?
but also to add debug information in the form of screenshots and console logs.
def test_ami(ami, subnet, security):
with new_keypair() as key:
with new_instance(key, ami, subnet, security) as id:
logger.info("Waiting for instance %s", id)
wait_for_online(id)
address = get_instance(id)['PublicIpAddress']
timer = Timer()
for seconds in SNAPSHOT_TIMES:
timer.wait_till(seconds)
screenshot(id, "screenshot_at_%d_seconds.jpg" % seconds)
if test_ping(address):
break
test_server(address)
consolelog(id, "console.log")
Taking the screenshots every second at 1-15 seconds, then every 15 up to 300 seconds helped debug many of the boot up errors, especially on Windows. Collecting the console log sorted out many of the others.
The functions are easily written too:
def screenshot(id, filename):
output = subprocess.check_output([
"aws", "ec2", "get-console-screenshot",
"--instanceid", id])
data = json.loads(output)['ImageData']
with open(filename, 'wb') as handle:
handle.write(base64.b64decode(data))
the corresponding consolelog function is almost identical but using get-console-output instead
of screenshot.
Results
We got the final result to look a bit like the following:
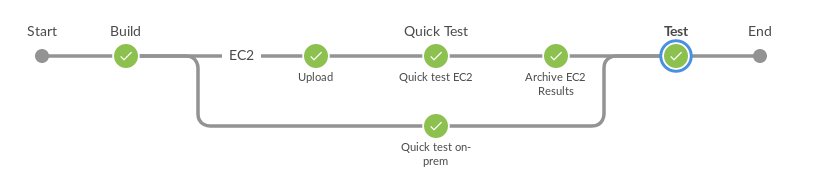
After the tool was built it was uploaded and tested on EC2 at the same time a quick sanity test was performed on-prem. Once EC2 was complete (and even if it failed…) we got a set of screenshots and logs from the EC2 console to figure out what happened.
All in all the quick test on EC2 + build took 15 minutes… but saved hours of agony!